
Nous allons voir dans cet article l’organisation des données de Drupal
Une base de données est composée de tables, chaque table est composée de champs et chaque champ contient des données.
Gestion des rôles et utilisateurs
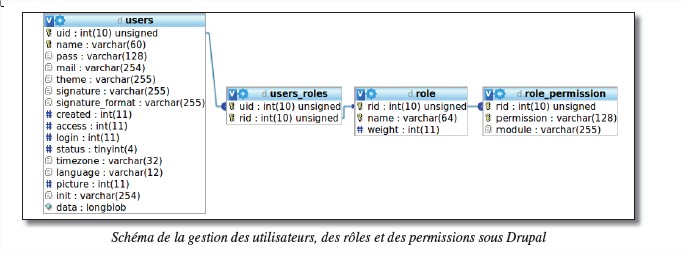
Chaque utilisateur possède un ou plusieurs rôles qui lui procurent des permissions. La liste des rôles est stockée dans la table role et la liste des permissions dans la table role_permission
On dit que le champ rid de la table role_permissions est une clé étrangère liée au champ rid de la table role.
Des rôles sont attribués aux utilisateurs. Un utilisateur peut posséder plusieurs rôles et un rôle peut être possédé par un utilisateur. Il est donc nécessaire d’avoir une table contenant tous les couples utilisateur/rôle possible. Cette table est la table users_roles
Gestion des nodes

Dans la table node, vous trouveriez des informations telles que le langage, lé numéro de l’utilisateur qui a créé la node (uid), son titre (title), ses options de publication (sticky, promote) etc. Dans cette table, le seul champ présent est le titre, les autres champs sont stockés dans d’autres tables qui seront étudiées par la suite
La table Node est reliée à la table node_type qui définit les types de nodes (article, page, sondage, custom_post_type)
Gestion des commentaires

La table comment contient les informations liées aux commentaires. Elle contient deux clés étrangères, uid qui indique quel est l’auteur du commentaire et nid qui indique a quelle node se rattache le commentaire.
Le champ pid est également une clé étrangère de la table comment elle même qui indique quel est le commentaire (cid) parent ( dans le cas ou les commentaires sont hiérarchisés)
Gestion des champs

Tous les champs se rapportant aux nodes se trouvent dans les tables préfixées par la chaîne field_data_*
Lorsqu’un nouveau champ est créé, une table est créée (champ body => field_data_body, champ prix => field_data_prix)
Le champ entity_type de chaque table field_data_* indique quel est le type d’entité(node, users, comment,taxonomy) à laquelle il se rattache. Le champ bundle lui, stocke le type de contenu (article, page, recette) lorsque entity_type est une node. Le champ entity_id contient le numéro de l’entité (nid lorsque entity_type est une node)
Les tables field_data peuvent avoir des champs différents en fonction du type de champ, voici trois exemples de tables :
- le contenu du champ body, de type Texte long et résumé, est stocké dans la table field_data_body (le contenu (body_value), le résumé (body_summary) et le format d’entrée sous forme de clé étrangère (body_format) sont stockés dans la table
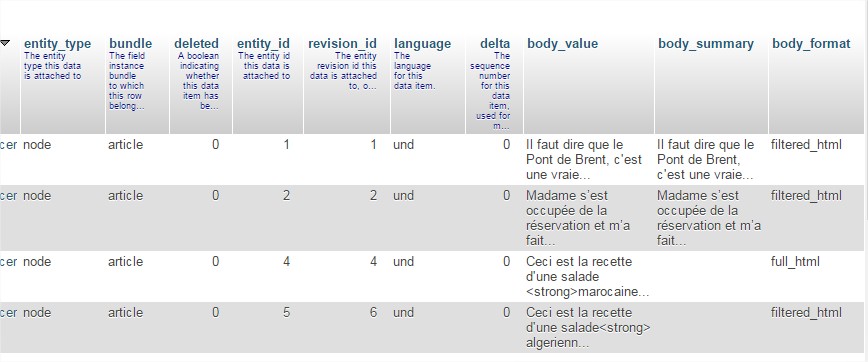
- le contenu du champ image, de type image est stocké dans la table field_data_field_image. Cette table contient un lien vers le fichier sous forme de clé étrangère (field_image_fid) et les paramètres alt (field_image_alt) et title (field_image_title)
- le contenu du champ Prix, de type float est stocké dans la table field_data_field_prix. Cette table contient uniquement le réel stocké (field_prix_value)
Cas d’un champ contenant plusieurs valeurs

Un champ peut contenir un nombre de valeurs illimités. Il y aura donc plusieurs lignes dans la table field_data_field_ingredients qui auront un champ entity_type identique. Le champ delta permet de connaitre l’ordre des lignes.
Gestion des formats d’entrée
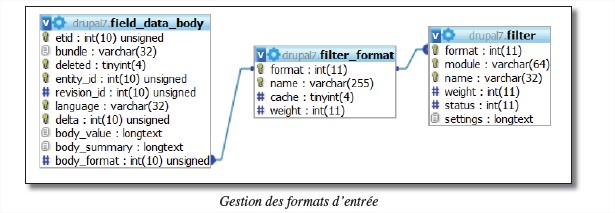
Un champ personnalisé peut être associé à un format d’entrée. C’est le cas par exemple du champ body d’un article ou d’une page
Un champ contenant un format d’entrée possède une clé étrangère(ici, body_format) la liant à la table filter_format. Chaque format d’entrée contient ensuite un ou plusieurs filtres de la table filter
Paramètres des champs
 Des fois on peut ajouter le même champ sur plusieurs type de contenus par exemple (article et custom_type_content), Les informations relatives à ce champ sont donc stockées dans la table field_data_field_image (j’ai pris l’exemple du champ Image). Cependant, il est possible de définir certaines options spécifiquement pour chaque champ;
Des fois on peut ajouter le même champ sur plusieurs type de contenus par exemple (article et custom_type_content), Les informations relatives à ce champ sont donc stockées dans la table field_data_field_image (j’ai pris l’exemple du champ Image). Cependant, il est possible de définir certaines options spécifiquement pour chaque champ;
Les champs field_id et field_name indiquent le numéro et le nom du champ (body, field_prix, etc), entity_type le type d’entité et bundle le nom de l’entité.
Les champs des autres types d’entité
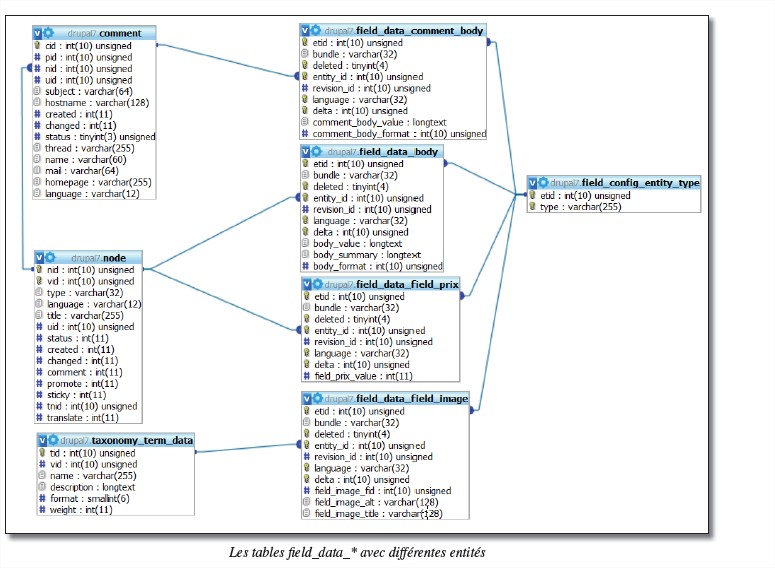
Les tables sont organisées de la même façon que pour les entités node : une table field_data_* par champ et un numéro d’entité dans le champ entity_id (nid pour les nodes, tid pour les vocabulaires, cid pour les commentaires)
Le champ bundle change alors selon le type d’entité.
Les révisions des champs

Chaque node peut avoir une révision ou version. La table node contient deux clés : nid (numéro de la node) et vid (numéro de révision en cours). Elle est reliée à la table node_revision qui contient les données des différentes révisions de node.
Pour chaque table field_data_*, une table field_revision_* existe. Ces deux tables sont reliées de la même manière que les tables node et node_revision. Elles permettent de stocker les révisions de chaque champ.
Relation entre les vocabulaires et les nodes

La table taxonomy_vocabulary contient la description des vocabulaires. La table taxonomy_term_data contient les descriptions de chaque terme.
La table taxonomy_index est une table de transition entre taxonomy_term_data et node car une node peut avoir plusieurs termes et un terme peut être relié à plusieurs nodes
Référence :